![]()
|
Today’s post involves massive multidimensional datasets, machine learning, and being able to predict the future. Sound interesting? Researchers are the National Institute on Aging and the University of Illinois at Urbana–Champaign have analysed longitudinal clinical data from the Parkinson’s Progression Marker Initiative (PPMI) and they have found three distinct disease subtypes with highly predictable progression rates. NOTE: Reading about disease progression may be distressing for some readers, but please understand that this type of research is critical to helping us better understand Parkinson’s. In today’s post, we will look at what the researchers found and discuss what this result could mean for the Parkinson’s community. |

Source: ScienceMag
Today I am going to break one of the unwritten rules of science communication (again) .
Until a research report has been through the peer-review process you probably should not be discussing the results in the public domain.
But in this particular case, the research is really interesting. And it has been made available on the OPEN ACCESS preprint depository website called BioRxiv.
![]()
Source: BioRxiv
I should add that this is not the first time we have discussed manuscripts on BioRxiv (Click here and here to read other post on Biorxiv manuscripts). We are regular rule breakers here at the SoPD.
So what does the new research investigate?
Researchers from the National Institute on Aging, National Institutes of Health and the University of Illinois Urbana-Champaign have used longitudinal clinical data from the Parkinson’s Progression Marker Initiative (PPMI) to determine if they could firstly divide the Parkinson’s population into subtypes – different groups based on their clinical features. Next, the investigators wanted to determine if they could use that information to predict the course of Parkinson’s progression in these groups.
What is the PPMI?
Started in 2010, the Parkinson’s Progression Marker Initiative (PPMI) is a major observational clinical study which aims to identify biomarkers of Parkinson’s progression. A biomarker is an objectively measurable physical characteristic associated with a condition.
The project is doing this by assessing an international collection of people with Parkinson’s, which includes building the largest collection of clinical, imaging and biologic specimens ever created in the Parkinson’s community.
The project is being conducted in the United States, Europe, Israel, and Australia and it is sponsored by The Michael J. Fox Foundation.

How does the project work?
The PPMI is studying volunteers with and without Parkinson’s for up to five years to better understand biologic changes over time. Study participants are required to complete a series of motor assessments, brain imaging (DaTSCAN and MRI), have biological samples collected (blood, spinal cord fluid, and urine), do a smell test, have neuropsychiatric/cognitive assessments, and have their DNA sequenced. It is a very thorough analysis of the individual.

Source: MJFF
Importantly, ALL test data and specimens collected as part of the study are store at central study repositories and made available to researchers through this PPMI website. Investigators from academic and industry organisations are only allowed to access the repository after being vetted through a review process.
The goal of the PPMI project is to identify biomarkers that will allow for:
- Earlier diagnosis
- Better tracking of Parkinson’s
- More efficient testing of new therapies
And this is a different project is different to the Fox Insight initiative that the Michael J Fox Foundation also supports.
If you are you are interested in getting involved in the PPMI study or simply want to learn more about – Click here. There is also a ‘Questions & Answers’ page for those seeking more details – Click here.
Interesting. So what did the new research report find?
Here is the pre-print manuscript:
Title: Predicting onset, progression, and clinical subtypes of Parkinson disease using machine learning
Authors: Faghri F, Hashemi SH, Leonard H, Scholz SW, Campbell RH, Nalls MA, Singleton AB
Database: BioRxiv
DOI: https://doi.org/10.1101/338913 (This manuscript is OPEN ACCESS if you would like to read it)
In this study, the researchers wanted to address the need for predictive biomarkers that could facilitate early detection and identification of distinct subtypes of Parkinson’s, which in turn could help to improve predictions of the course of the condition in individuals. In order to do this, the investigators utilised both unsupervised and supervised machine learning approaches.
What is machine learning?
Machine learning is a field of artificial intelligence programming in which statistical techniques are used to give computers the ability to “learn” – or progressively improve performance on a specific task with data, without being explicitly programmed to do so.
It’s pretty complicated stuff – well over my head.
This video will hopefully help you to understand:
Ok, so what data did the researchers use?
In their analysis, the researchers used longitudinal clinical data from the Parkinson Disease Progression Marker Initiative (PPMI) which we mentioned above. They used data collected from this database to identify subtypes of Parkinson’s and to predict the progression of the condition for each subtype. This analysis involved data from 328 cases of Parkinson’s.
The resulting models that were generated from the machine learning process were validated using an independent, clinically well-characterised cohort from the Parkinson Disease Biomarker Program (PDBP).

The PDBP database is similar to the PPMI database, but it contains information from only 112 cases of Parkinson’s.
And what did the researchers find?
The researchers pooled all of the data together – which included multiple visits to clinical assessments over the 4 year period in the PPMI data (and 3 year period in the PDBP data) – and they looked for signs of clustering within the data.

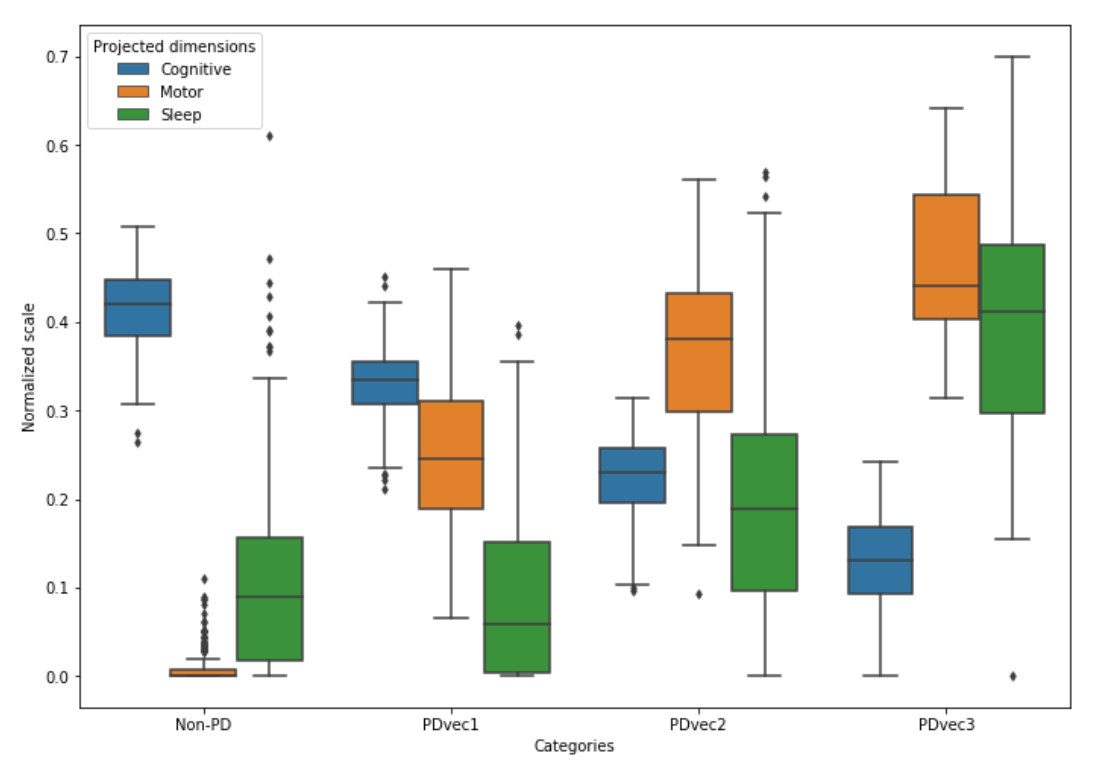
Fundamental to the clustering in this study was the use of three main dimensions: motor, cognition and sleep-related issues.
And using these three components, the machine learning analysis revealed three main subtypes of Parkinson’s relating to rates of progression:
- PDvec1
- PDvec2
- PDvec3
And these sub-populations exhibited highly predictable rates of progression over the four years. In the image below, PDvec1 is represented in green, PDvec2 is in yellow/orange, PDvec3 is in blue, and controls are presented in red (the higher the score, the worse the performance):

There was a clear trend for increased sleep and motor disturbances after four years in fast progressors (PDvec3) compared to the slower progressing subtype (PDvec1) which seems to have relatively more cognitive issues early on.
The investigators next looked for any possible genetic association in these three subtypes, but the sample of only 300 individuals was very small. Given this situation, they developed a genetic risk score which amounted to any of the recognised Parkinson’s-associated genetic mutations/variants being present in each individual. Intriguingly, the results of this analysis indicated that the genetic risk score was weakly but significantly associated with a decreased risk of being in the PDvec3 subtype (most progressive form of PD) and an increased risk of belonging to the PDvec1 subtype (most mild version of PD).
The researchers concluded their study by suggesting that these “data-driven results enable clinicians to deconstruct the heterogeneity within their patient cohorts” (heterogeneity being the variability between people with Parkinson’s in the symptoms). In addition, they concluded that “this knowledge could have immediate implications for clinical trials by improving the detection of significant clinical outcomes that might have been masked by cohort heterogeneity”.
What if I think I’m in the rapid progression ‘PDvec3’ population?
OK, a couple of things to bear in mind when reading this post:
Firstly, this post was not shared to freak anyone out – some researchers have looked at a large set of data and found some interesting patterns. There is a great deal of variability within the data.
Second, this it is important to remember that this ‘three subset’ model is just one interpretation of the data based on just three dimensions of clustering (and it is unlikely that the situation with Parkinson’s will be as simple as this!).
Third, readers should not be self-diagnosing themselves based on anything they read here. They are best advised to discuss matters with your clinician who will be able to provide them with a more unbiased opinion.
Has anyone ever looked for subtypes of Parkinson’s like this before?
Yes, but the beauty of this new study is that it has longitudinal data from multiple visits AND the model was validated against a second database.
Previous attempts at this sort of analysis also found subtypes. For example:

Title: New Clinical Subtypes of Parkinson Disease and Their Longitudinal Progression: A Prospective Cohort Comparison With Other Phenotypes.
Authors: Fereshtehnejad SM, Romenets SR, Anang JB, Latreille V, Gagnon JF, Postuma RB.
Journal: JAMA Neurol. 2015 Aug;72(8):863-73.
PMID: 26076039
In this study, 113 people with idiopathic (that is ‘spontaneous’ or no genetic association) Parkinson’s were enrolled. A comprehensive set of motor and non-motor features of Parkinson’s were assessed during the first visit. A follow-up assessment was made 4.5 years later on 76 of the participants.
In their analysis in this study, the investigators used the presence of orthostatic hypotension, mild cognitive impairment, rapid eye movement sleep behaviour disorder (RBD), depression, anxiety, and the Unified Parkinson’s Disease Rating Scale (UPDRS Part II and Part III) scores to cluster the data.
What is orthostatic hypotension?
Orthostatic hypotension – also called postural hypotension – is a form of low blood pressure that occurs when you stand up.
The researchers found three subtypes of Parkinson’s:
- Cluster I – 43 participants were termed ‘mainly motor‘ based on baseline features. They were characterised by the absence of orthostatic hypotension and a low frequency of RBD sleep issues. Some cognitive issues were seen in 19 of these individuals, but depression and anxiety were relatively mild.
- Cluster 2 – 40 participants were termed ‘diffuse‘ based on baseline features. They were characterised by the presence of both orthostatic hypotension and cognitive issues in all 40 subjects, with a very high frequency of RBD (37 of the participants).
- Cluster 3 – 30 participants were termed ‘intermediate‘ based on baseline features. They were characterised by significantly worse performance on motor features than the other clusters. All displayed orthostatic hypotension, but none had cognitive issues.
At the follow up analysis (4.5 years later), cluster II had a worse outcome, with more rapid progression in all domains, including cognition, while clusters I and III experienced more moderate progression. But given the size of the follow up group (only 76 of the participants), it is difficult to draw too many conclusions from this longitudinal aspect.
Given this situation, the researchers decided to replicate this study using data from the Parkinson’s Progression Markers Initiative (PPMI – mentioned above). That analysis was published last year (2017):

Title: Clinical criteria for subtyping Parkinson’s disease: biomarkers and longitudinal progression.
Authors: Fereshtehnejad SM, Zeighami Y, Dagher A, Postuma RB.
Journal: Brain. 2017 Jul 1;140(7):1959-1976.
PMID: 28549077
In this study, the researchers collection data from the PPMI study for 421 people with newly diagnosed Parkinson’s. They clustered the data based on:
- cognitive impairment
- rapid eye movement sleep behaviour disorder
- dysautonomia
And before you ask: dysautonomia is a disorder of autonomic nervous system, which results in symptoms such as orthostatic hypotension, constipation, breathing problems, etc.
Again their analysis identified three distinct subtypes of Parkinson’s:
- Cluster #1 – 223 people were classified as ‘mild motor’ (defined as composite motor and all three non-motor scores below the 75th percentile)
- Cluster #2 – 52 as ‘diffuse’ (composite motor score plus either ≥1/3 non-motor score >75th percentile, or all three non-motor scores >75th percentile)
- 146 as ‘intermediate’.
Brain imaging data suggested that there was more atrophy (or shrinkage) in Parkinson’s associated parts of the brain in the cluster #2 (diffuse) subtype, with cluster #1 (mild motor) subtypes having the least amount of atrophy.
Although the duration of Parkinson’s at initial visit and follow-up time were very similar between subtypes, people within the ‘diffuse’ subtype of Parkinson’s progressed faster in overall prognosis, with greater decline in cognitive ability and in dopamine function (based on brain imaging) after an average of 2.7 years. These ‘diffuse’ individuals displayed a more Alzheimer’s-like combination of proteins in their cerebrospinal fluid when these samples were analysed.
Interestingly, when the genetic profile of the individuals was analysed in this study, the results showed that the role of currently known genetic risk factors (when combined), was much less influential than the clinical features for determining subtype and progression.
In their conclusion, the investigators suggested that a future “exploration of the underlying pathophysiologic differences between various Parkinson’s subtypes will shed light on the underlying mechanisms for this variability. Ultimately, this knowledge could be used to develop a more efficient personalized approach for clinical trials and treatment strategies for individuals with different subtypes of Parkinson’s“.
So what does it all mean?
This kind of post is hard to write, but the nuts and bolts of the content are absolutely essential for our understanding and better management of Parkinson’s.
Being able to better predict onset and course of different subtypes of Parkinson’s will have major benefits for the community as a whole. For sufferers, a better understanding of the different subtypes will lead to more specialised treatment approaches that will be focused on specific components. At the very least, more tailored treatments will lead to better quality of life.
For the research community, a more thorough breakdown of the subtypes of Parkinson’s will result in a better understanding of the condition as a whole (are we actually dealing with one condition? Or is it a case of multiple conditions under the same umbrella label of PD?). Subtyping will allow for more focused research on the underlying biology of the conditions (perhaps
Better models of predicting the course of particular subtypes of Parkinson’s would also have benefits for clinical trials. More accurate subtypes of Parkinson’s could potentially result in shorter and smaller clinical trial, and be more likely to detect smaller effects. All of which would decrease the cost of the clinical trial process and reduce the exposure of pharmaceutical companies to an expensive and failure-prone area of treatment development.
All of these benefits could potentially arise from longitudinal projects, but only if the current results can be validated across other datasets. Thus, as the researcher in the BioRxiv manuscript suggest in their discussion of the results that “there is a critical need is the expansion or replication of efforts such as PPMI or PDBP” (the discussion in all of the reports mentioned in this post suggested the same thing). It would be particularly interesting to see if other regions of the globe see similar results (for example, Asian nations – an opportunity for someone to initiate a major project there!).
The banner for today’s post was sourced from MJFF

Personally I have been dismayed that prognostic information seems to be a closely guarded secret among clinicians and have spent countless hours poring over PubMed studies looking for information all the while feeling that my medical team knew stuff that they didn’t want to share. We’re not so delicate! We want information. We can see what’s happening to us. We’re older than all of you. We can handle the truth! If you have prognostic info you should share it. Medical professionals who try to protect us are being patronizing! Doctors should wise up! This is not directed toward researchers.
LikeLike
Interesting. I will try to do what you said we shouldn’t do – predict outcome based on genes. Seems like the new study said genes recognized as PD related lead to a milder form of PD, but the later study said there was little relationship?
“genetic risk score was weakly but significantly associated with a decreased risk of being in the PDvec3 subtype (most progressive form of PD) and an increased risk of belonging to the PDvec1 subtype (most mild version of PD)”
“Interestingly, when the genetic profile of the individuals was analysed in this study, the results showed that the role of currently known genetic risk factors (when combined), was much less influential than the clinical features for determining subtype and progression.”
“readers should not be self-diagnosing themselves based on anything they read here.”
LikeLike